Introduction
This blog clearly explains the difference between XPath and CSS Selector. The concept of XPath and CSS Selector is not clear as they have similarities in syntax. In web automation testing with Selenium, choosing the right method to locate and interact with web elements is important. Most of the time it falls in the best practice to choose the id but what ID the element does not have it. In that case, there are two popular methods to locate elements; they are XPath and CSS Selector. Here the differences between XPath and CSS Selector are given, which will help you in selecting the appropriate method for locating the element.
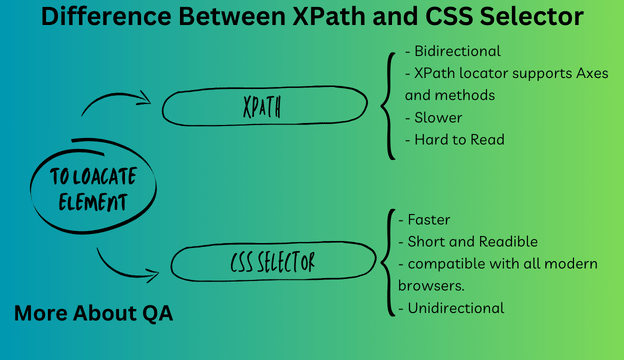
Difference Between XPath and CSS Selector
Here are the difference between XPath and CSS Selector:
| About XPath | About CSS Selector |
| bidirectional you can traverse elements from parent to child and vice versa | CSS selector is unidirectional |
| XPath’s performance is slower | CSS selector is comparatively faster than XPath |
| XPath supports construction based on text | No such Support |
| XPath starts with / or // followed by a tag name or wildcards like * | CSS Selector uses “#” for id and “.” for classes |
| XPath has Axes to construct complicated selector problems | No such Support |
| Xpath is hard to read as it grows | CSS Selector is more readable than XPath |
Syntax and Format
XPath starts with // and follows the format:
//tagname[@attribute='value']And CSS Selector uses a simpler syntax:
tagname[attribute='value']This syntax distinction can make a significant difference in readability.
Example | Difference between XPath and CSS selector
Here is practical example for using both methods for locating elements, Below is the HTML code for XPath.
<!DOCTYPE html>
<html>
<head>
<title>XPath Example</title>
</head>
<body>
<div id="container">
<h1>Welcome to XPath Example</h1>
<p>This is a paragraph.</p>
<ul>
<li class="item">Item 1</li>
<li class="item">Item 2</li>
<li>Item 3</li>
</ul>
<div>
<span>Span Text</span>
</div>
</div>
</body>
</html>
To find XPath with various way:
Select the <h1> element:
/html/body/div/h1Select the <p> element with text “This is a paragraph.”:
//p[text()='This is a paragraph.']Select the <div> element with the ID “container”:
//*[@id='container']Select the <li> element with the text containing “Item”:
//li[contains(text(), 'Item')]Now lets try to understand and locate elements using CSS Selector, below is the HTML code for CSS Selector.
<!DOCTYPE html>
<html>
<head>
<title>CSS Selector Example</title>
</head>
<body>
<div id="id1">This is an element with ID</div>
<div class="class1">This is an element with Class</div>
<img alt="abc" src="image.jpg"> <!-- Element with alt attribute -->
<div>
</body>
</html>
Here is the different ways to construct CSS Selector.
/* Select the element with ID */
#id1
/* Select the element with Class */
.class1
/* Select the image with alt attribute equal to "abc" */
img[alt='abc']Tools For Validating XPath and CSS Selector
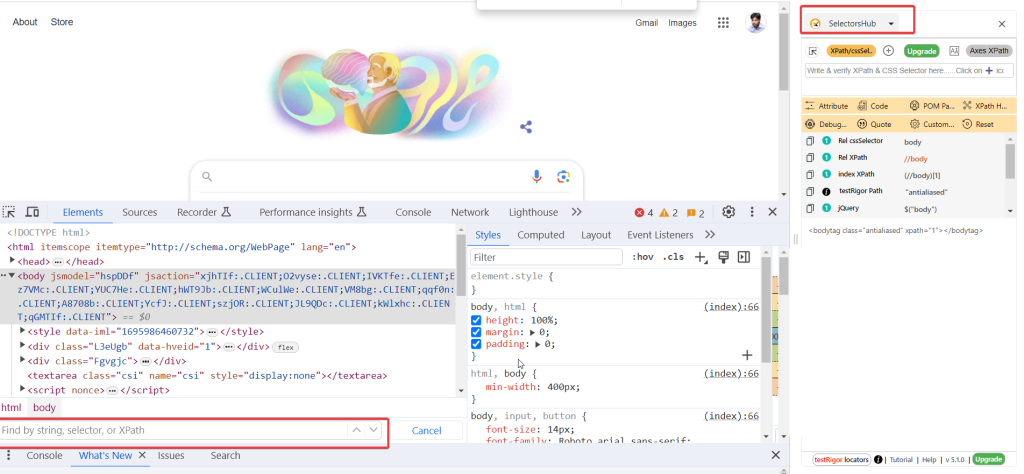
Various tools and plugins are available which you can use to generate XPath and CSS Selector whit them, i will always suggest to write it on your own, and you can validate it by opening the debugger view of the browser and the press CTR+F , where you can validate your created XPath or CSS Selector, However if you are lacking in expertise, then i would suggest to go with a chrome extension that is, Selector Hub. see snap below.
Traversal in the DOM
Both XPath and CSS Selector allow you to traverse the Document Object Model (DOM) in a forward direction, moving from a parent element to a child element.
I vote to use CSS selector as XPath will not work if the DOM changes.
Performance
In performance, CSS Selector tends to outperform XPath. XPath engines vary between browsers, making them less consistent, and they can be slower. Internet Explorer lacks a native XPath engine, causing Selenium to inject its own, which can lead to further inconsistencies.
CSS selectors are way faster than XPath because they are unidirectional; they can search for elements in the DOM tree quickly.
Absolute and Relative XPath
XPath can be categorized into two types: absolute and relative. Absolute XPath starts from the root node of the DOM, while relative XPath doesn’t require starting from the root.
CSS Selectors inherently work in a “relative” manner, meaning they always consider the current context (a specific element in the DOM) as the starting point for their search.
Advantages of XPath | Top 4 Benefits
XPath supports all major test automation libraries, frameworks, and programming languages.
- It is bidirectional.
- It has support for both XML and HTML documents.
- Though it is compatible with modern browsers it may not be as compatible with older versions of Internet Explorer
- XPath locator supports Axes and methods. With that, you could solve complex locator problems.
Disadvantages of XPath
- No doubt, experts claim that XPath locators are comparatively slow, which can affect the overall performance of the test suite.
- When XPath is associated with more than one element in the DOM tree, it tends to break as and when new element-level changes are introduced.
- XPath is hard to maintain as when XPath becomes complicated its readability decreases.
Advantages of CSS Selectors
- CSS Selectors are way faster than XPath.
- They are easy to learn and are more.
- CSS selectors are compatible and support all modern browsers.
- They are more reliable as it is mostly tied to a single HTML element.
Disadvantages of CSS Selectors
- You cannot construct the selectors based on visible text.
- CSS Selector mainly works in one direction, allowing you to find child elements within parent elements. This can be challenging when dealing with complex situations.
- Unlike XPath, CSS Selectors lack specific tools (like Axes in XPath) for handling complicated element selections.
- If the webpage doesn’t include attributes for elements in the code, creating a CSS Selector can be tough, and it might not work reliably.
- CSS Selectors can’t be easily created based on what text is visible on the webpage.
Other Methods to Locate Elements
Apart from XPath and CSS Selectors, there are many other methods and ways for locating elements on a web page when performing automation or web scraping. Here are some commonly used alternatives:
ID: In most of the cases elements have id attributes, that is unique, you can use the following method to locate the element By.id() in Selenium, Appium, and other automation technologies. For example:
WebElement element = driver.findElement(By.id("elementId"));
Name: This is another approach to locate Element, use the method By.name() like:
WebElement element = driver.findElement(By.name("elementName"));
Link Text and Partial Link Text: For Links with specific text we use By.linkText() and By.partialLinkText() methods to locate the element:
WebElement link = driver.findElement(By.linkText("Link Text"));
WebElement partialLink = driver.findElement(By.partialLinkText("Partial Text"));
Tag Name: For any HTML tag we can use By.tagName() method in order to locate it:
List<WebElement> elements = driver.findElements(By.tagName("div"));
Class Name: Elements with specific class attributes are located using By.className() method:
WebElement element = driver.findElement(By.className("elementClass"));
Name Attributes in Form Elements: Form elements like input, textarea, and button can often be located using their name attributes:
WebElement inputField = driver.findElement(By.name("fieldName"));
Link Text in Tables: When dealing with tables, you can locate elements within table cells using their link text or content:
WebElement cell = driver.findElement(By.xpath("//table//td/a[text()='Link Text']"));
CSS Selectors (Alternative Syntax): Besides the standard CSS Selector syntax, you can also use alternative syntax for CSS Selectors in Selenium:
WebElement element = driver.findElement(By.cssSelector("[attribute='value']"));
Accessibility Locators: Selenium supports accessibility locators for finding elements based on their accessibility properties, which is useful for making web applications more accessible. Examples include By.accessibilityId() for mobile apps and By.ariaLabel() for web apps.
Here is summary table of the approaches mostly used in Xpath.
| # | Xpath Method | Syntax or Example |
| 1 | Relative xpath for a link. | //div[@id=’navbar’]//ul/li[1]/a |
| 2 | With Text function to create xpath | //div[@class=abc]//a[text()=Click Me’] |
| 3 | With Contains to locate the elements: | //div[@id=abc]//a[contains(@href,Click me) |
| 4 | With Starts-‐to locate element: | //tag[starts-with(attribute, ‘value’)] |
| 5 | Preceding Sibling | Xpath to the element //preceding-sibling:: <tag> |
Note: Don’t always use “*”, rather use the tag name.
Related post: Setup Selenium in IntelliJ with TestNG Framework
Conclusion | Difference between XPath and CSS selector
Now you should have a clear understanding of the difference between XPath and CSS Selector, to sum up, I would suggest that ID is best because it rarely changes, which requires less maintenance and fewer false failures.
XPath is not the best if the Dom changes XPath is more likely to be disrupted. Still, one could use it based on the extraordinary features it offers to locate elements based on different parameters.
CSS selector is another method that could be used based on its performance.